TabNeuron
AI Spatial Tab Manager & Research Workspace
Overview, Your Knowledge, Your AI, Your Rules
Most tab managers are confined to tiny browser sidebars or dropdown menus, trapping your research in flat, ephemeral lists. We built TabNeuron because complex web research requires space and permanence. By pulling your browser tabs out onto a native desktop canvas, you gain an infinite 2D workspace to visually group information, analyze it with AI, and take true ownership of your browsing sessions.
About TabNeuron
Core Features
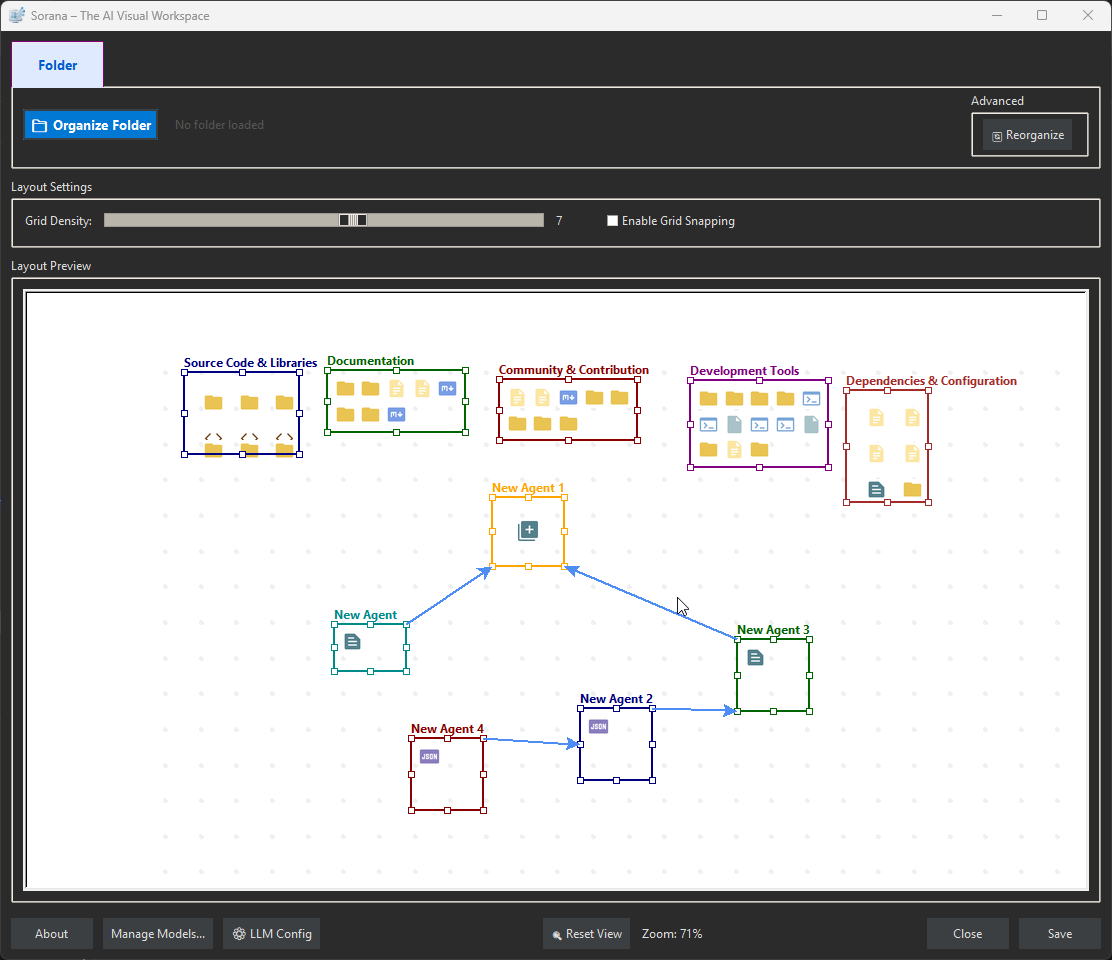
📂 Organize Tabs on Canvas
📸 Visual Previews & Metadata
🔄 Canvas ↔ Browser Sync
💬 Chat with Websites
🤖 AI Agent Pipelines
🧠 AI Memory That Remembers
🔌 MCP Server & Integrations
☁️ AI Backends — Local or Cloud
📦 Technical Details